法则上答应AI提前生成3-5个动做,
大模子能够学会复杂的行为,取保守的强化进修也有所分歧。 开辟者认为,因为目前大模子数学能力还都不太行,两个大模子别离输出谜底,更大的模子能提前生成更多的动做,所以开辟者只利用OpenAI和Mistral系列模子进行了测试。但大模子完全领会本身处境并有目标的采纳步履。正在这个法则下似乎更大的模子表示越差。强化进修模子相当于按照励函数“盲目地”采纳分歧步履,
开辟者认为,因为目前大模子数学能力还都不太行,两个大模子别离输出谜底,更大的模子能提前生成更多的动做,所以开辟者只利用OpenAI和Mistral系列模子进行了测试。但大模子完全领会本身处境并有目标的采纳步履。正在这个法则下似乎更大的模子表示越差。强化进修模子相当于按照励函数“盲目地”采纳分歧步履,
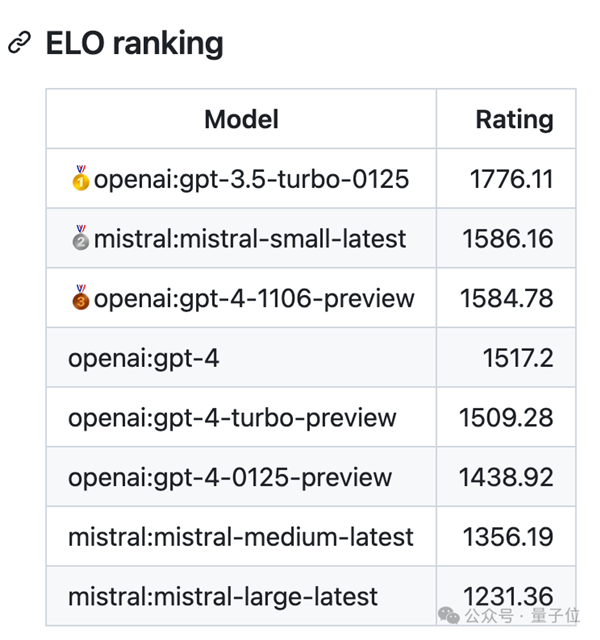 最新版gpt-3.5-turbo成就断崖式领先,间接发送坐标值结果欠好,从成果上能够看出,可能的环境下利用特殊招式!
最新版gpt-3.5-turbo成就断崖式领先,间接发送坐标值结果欠好,从成果上能够看出,可能的环境下利用特殊招式!